
Text-to-Speech Service
Deliver natural-sounding speech with configurable voices, streaming playback, and file-based output. All endpoints use a consistent JSON payload via POST requests, making integration simple and straightforward.
Need an API Key? If you don't have an API key yet, you can create one here: https://playground.induslabs.io/register
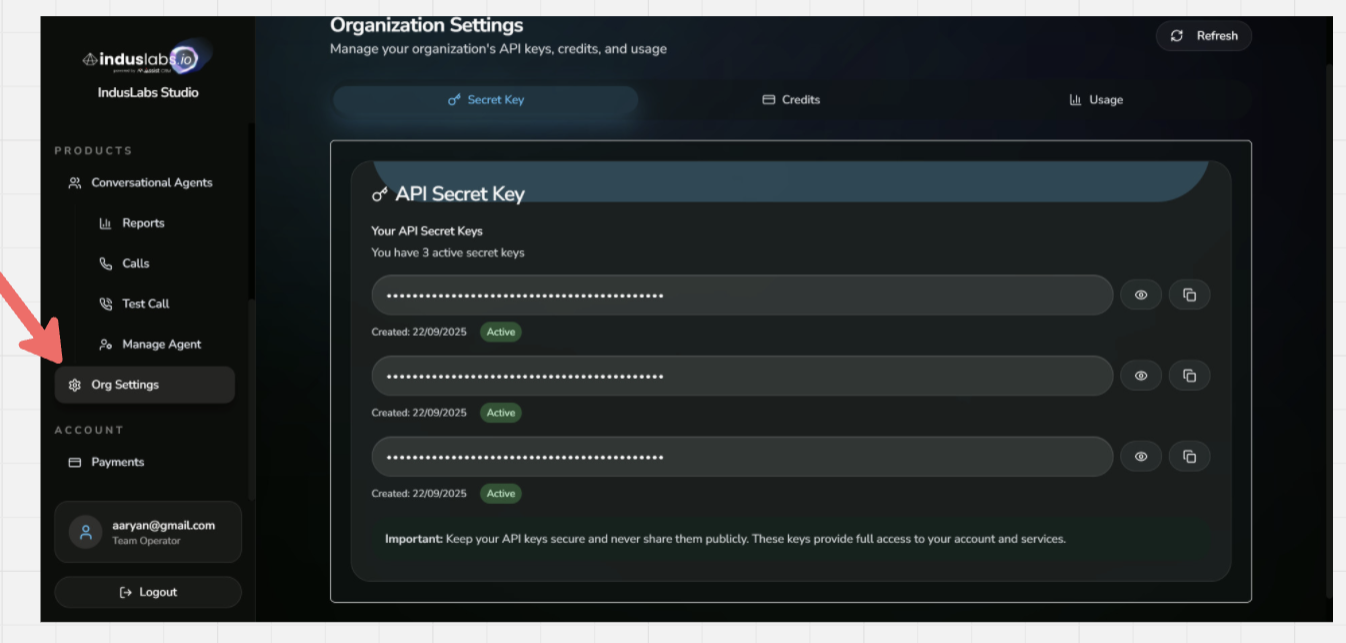
Screenshot: where to find your API key. Create one at playground.induslabs.io/register
{
"text": "Hello, this is a test request.",
"voice": "Indus-hi-maya",
"output_format": "wav",
"model": "indus-tts-v1",
"api_key": "YOUR_API_KEY",
"normalize": true,
"stream": true,
"speed": 1,
"pitch_shift": 0,
"loudness_db": 0,
"sample_rate": 24000
}
Payload Fields
| Name | Type | Default | Description |
|---|---|---|---|
text | string | required | The text to be synthesized into speech. |
voice | string | Indus-hi-maya | The voice model to be used (e.g., "Indus-hi-maya"). |
output_format | string | wav | Audio format for output (e.g., "wav", "mp3", "pcm"). |
model | string | indus-tts-v1 | The TTS model to use (e.g., "indus-tts-v1"). |
api_key | string | required | Authentication API key. |
normalize | boolean | true | Whether to normalize text before synthesis (default: true). |
stream | boolean | true | Whether to stream the output (default: true). |
speed | number | 1 | Speed of speech synthesis (default: 1). |
pitch_shift | number | 0 | Pitch shift adjustment (default: 0). |
loudness_db | number | 0 | Loudness adjustment in decibels (default: 0). |
sample_rate | number | 24000 | Audio sample rate in Hz. Accepted values: 24000 (recommended), 16000, 8000. |
/v1/audio/speechSynthesize Speech
This endpoint is used to synthesize speech (TTS - Text-to-Speech) and stream the audio data.
- Converts input text into speech audio.
- Uses credit system authentication.
- Returns audio data directly in the response body.
- Supports streaming for real-time audio playback.
Inputs
| Name | Type | Default | Description |
|---|---|---|---|
text | string | required | The text to be synthesized into speech. |
voice | string | Indus-hi-maya | The voice model to be used (e.g., "Indus-hi-maya"). |
output_format | string | wav | Audio format for output (e.g., "wav", "mp3", "pcm"). |
model | string | indus-tts-v1 | The TTS model to use (e.g., "indus-tts-v1"). |
api_key | string | required | Authentication API key. |
normalize | boolean | true | Whether to normalize text before synthesis (default: true). |
stream | boolean | true | Whether to stream the output (default: true). |
speed | number | 1 | Speed of speech synthesis (default: 1). |
pitch_shift | number | 0 | Pitch shift adjustment (default: 0). |
loudness_db | number | 0 | Loudness adjustment in decibels (default: 0). |
sample_rate | number | 24000 | Audio sample rate in Hz. Accepted values: 24000 (recommended), 16000, 8000. |
Outputs
| Status | Type | Default | Description |
|---|---|---|---|
200 OK | audio/wav | - | Returns synthesized speech audio as binary data. |
422 Validation Error | application/json | - | Validation failure. Inspect detail array. |
200 OK
Binary audio data (WAV format)
422 Validation Error
{
"detail": [
{
"loc": ["string", 0],
"msg": "string",
"type": "string"
}
]
}
/v1/audio/speech/fileSynthesize Speech File
This endpoint is used to synthesize speech (TTS - Text-to-Speech) and return the complete audio file as a downloadable file.
- Converts input text into speech audio.
- Returns the synthesized audio as a complete file download.
- Unlike /v1/audio/speech, this endpoint returns the full audio file at once.
Inputs
| Name | Type | Default | Description |
|---|---|---|---|
text | string | required | The text to be synthesized into speech. |
voice | string | Indus-hi-maya | The voice model to be used (e.g., "Indus-hi-maya"). |
output_format | string | wav | Audio format for output (e.g., "wav", "mp3", "pcm"). |
model | string | indus-tts-v1 | The TTS model to use (e.g., "indus-tts-v1"). |
api_key | string | required | Authentication API key. |
normalize | boolean | true | Whether to normalize text before synthesis (default: true). |
stream | boolean | true | Whether to stream the output (default: true). |
speed | number | 1 | Speed of speech synthesis (default: 1). |
pitch_shift | number | 0 | Pitch shift adjustment (default: 0). |
loudness_db | number | 0 | Loudness adjustment in decibels (default: 0). |
sample_rate | number | 24000 | Audio sample rate in Hz. Accepted values: 24000 (recommended), 16000, 8000. |
Outputs
| Status | Type | Default | Description |
|---|---|---|---|
200 OK | audio/wav | - | Returns the synthesized speech audio as a downloadable file. |
422 Validation Error | application/json | - | Validation failure. Inspect detail array. |
200 OK
Binary audio data (WAV format)
422 Validation Error
{
"detail": [
{
"loc": ["string", 0],
"msg": "string",
"type": "string"
}
]
}
/v1/audio/speech/previewSpeech Preview
This endpoint provides a preview of how text will be processed for speech synthesis without actually generating audio.
- Accepts input text and parameters, then shows how the text would be processed by the TTS system.
- Does not generate audio, only returns metadata and analysis of the input.
- Useful for estimating credits, duration, and validating parameters before synthesis.
Inputs
| Name | Type | Default | Description |
|---|---|---|---|
text | string | required | The text to be synthesized into speech. |
voice | string | Indus-hi-maya | The voice model to be used (e.g., "Indus-hi-maya"). |
output_format | string | wav | Audio format for output (e.g., "wav", "mp3", "pcm"). |
model | string | indus-tts-v1 | The TTS model to use (e.g., "indus-tts-v1"). |
api_key | string | required | Authentication API key. |
normalize | boolean | true | Whether to normalize text before synthesis (default: true). |
stream | boolean | true | Whether to stream the output (default: true). |
speed | number | 1 | Speed of speech synthesis (default: 1). |
pitch_shift | number | 0 | Pitch shift adjustment (default: 0). |
loudness_db | number | 0 | Loudness adjustment in decibels (default: 0). |
sample_rate | number | 24000 | Audio sample rate in Hz. Accepted values: 24000 (recommended), 16000, 8000. |
Outputs
| Status | Type | Default | Description |
|---|---|---|---|
200 OK | application/json | - | Returns detailed analysis including character count, word count, estimated duration, credit cost, and configuration details. |
422 Validation Error | application/json | - | Validation failure. Inspect detail array. |
200 OK
{
"analysis": {
"total_characters": 30,
"total_words": 6,
"estimated_duration_seconds": 2.4,
"estimated_credits": 0.04,
"chunking_strategy": {
"total_chunks": 1,
"max_words_per_chunk": 15,
"overlap_words": 0,
"chunks": [
{
"index": 0,
"word_count": 6,
"text_preview": "Hello, this is a test request.",
"is_final": true
}
]
}
},
"configuration": {
"voice": "Indus-hi-maya",
"model": "indus-tts-v1",
"output_format": "wav",
"stream": true,
"temperature": 0.6,
"max_tokens": 1800,
"top_p": 0.8,
"repetition_penalty": 1.1,
"bitrate": null
},
"user_info": {
"user_id": "USR_A3E785AF",
"credits_remaining": 399.58,
"tts_unit_cost": 1,
"sufficient_credits": true
},
"output_settings": {
"format": "wav",
"voice": "Indus-hi-maya",
"model": "indus-tts-v1",
"streaming": true,
"sample_rate": 24000,
"channels": 1,
"bit_depth": 16
},
"text_processing": {
"original_text": "Hello, this is a test request.",
"processed_text": null,
"normalization_applied": false,
"normalize_setting": true,
"character_change": 0
},
"size_estimates": {
"pcm_bytes": 115200,
"wav_bytes": 115244,
"mp3_bytes": 38400,
"target_format_bytes": 115244
}
}
422 Validation Error
{
"detail": [
{
"loc": ["string", 0],
"msg": "string",
"type": "string"
}
]
}
/api/voice/get-voicesList Available Voices
Retrieves the catalog of voices available for speech synthesis across multiple languages.
- Returns a comprehensive list of available voices organized by language.
- Each voice includes name, voice_id, and gender information.
- Supports multiple languages including Hindi, English, Bengali, Kannada, Marathi, Telugu, Arabic, and regional languages.
- No authentication required for this endpoint.
Outputs
| Status | Type | Default | Description |
|---|---|---|---|
200 OK | application/json | - | Returns voice catalog organized by language with name, voice_id, and gender for each voice. |
422 Validation Error | application/json | - | Validation failure. Inspect detail array. |
200 OK
{
"status_code": 200,
"message": "Voices fetched successfully",
"error": null,
"data": {
"hindi": [
{
"name": "Maya",
"voice_id": "Indus-hi-maya",
"gender": "female"
},
{
"name": "Urvashi",
"voice_id": "Indus-hi-Urvashi",
"gender": "female"
},
{
"name": "Aditi",
"voice_id": "Indus-hi-Aditi",
"gender": "female"
},
{
"name": "Arjun",
"voice_id": "Indus-hi-Arjun",
"gender": "male"
}
],
"english": [
{
"name": "Maya",
"voice_id": "Indus-en-maya",
"gender": "female"
},
{
"name": "Urvashi",
"voice_id": "Indus-en-Urvashi",
"gender": "female"
}
],
"bengali": [
{
"name": "Alivia",
"voice_id": "Indus-bn-Alivia",
"gender": "female"
},
{
"name": "Sayan",
"voice_id": "Indus-bn-Sayan",
"gender": "male"
}
],
"kannada": [
{
"name": "Aahna",
"voice_id": "Indus-bn-Aahna",
"gender": "female"
},
{
"name": "Chinmay",
"voice_id": "Indus-bn-Chinmay",
"gender": "male"
}
],
"arabic": [
{
"name": "Fatima",
"voice_id": "Indus-ar-Fatima",
"gender": "female"
},
{
"name": "Hamdan",
"voice_id": "Indus-ar-Hamdan",
"gender": "male"
}
]
}
}
422 Validation Error
{
"detail": [
{
"loc": ["string", 0],
"msg": "string",
"type": "string"
}
]
}
/v1/audio/speech_wsWebSocket Streaming Speech Synthesis
Real-time text-to-speech synthesis using WebSocket for bidirectional streaming. Perfect for live speech generation, voice assistants, and low-latency applications.
- 🔌 Persistent Connection: Maintains a WebSocket connection for real-time audio streaming.
- ⚡ Real-time Generation: Receive audio chunks as they are synthesized—no waiting for complete generation.
- 🎯 Low Latency: Optimized for live speech generation and real-time voice applications.
- 📊 Streaming Output: Get audio data progressively as binary chunks for immediate playback.
- 🔄 Bidirectional: Send synthesis request and receive audio chunks continuously.
- 🎵 Multiple Formats: Supports WAV, MP3, and other audio formats with configurable parameters.
Connect to: wss://voice.induslabs.io/v1/audio/speech_ws
Unlike REST endpoints, WebSocket maintains a persistent bidirectional connection for real-time streaming synthesis.
indus-tts-v1: Standard TTS model with broad language support.indus-tts-v3: Latest generation model with improved quality and naturalness.
WebSocket Message Flow
| Message | Type | Order | Description |
|---|---|---|---|
Initial JSON Request | JSON | first | Send complete request payload as JSON string including text, voice, model, and all parameters. |
Audio Chunks | binary | continuous | Raw audio data received as binary WebSocket frames (synthesized speech audio). |
Status Messages | JSON | intermittent | JSON messages with type "done" (synthesis complete) or "error" (processing failed). |
Request Parameters (JSON)
| Name | Type | Default | Description |
|---|---|---|---|
text | string | required | The text to be synthesized into speech. |
voice | string | required | The voice model to use (e.g., "Indus-en-Ember", "Indus-hi-maya"). |
output_format | string | wav | Audio format for output (e.g., "wav", "mp3"). |
stream | boolean | true | Whether to stream the output (default: true). |
model | string | indus-tts-v3 | The TTS model to use (e.g., "indus-tts-v1", "indus-tts-v3"). |
api_key | string | required | Authentication API key. |
normalize | boolean | true | Whether to normalize text before synthesis (optional). |
speed | number | 1 | Speed of speech synthesis (optional). |
pitch_shift | number | 0 | Pitch shift adjustment (optional). |
loudness_db | number | 0 | Loudness adjustment in decibels (optional). |
sample_rate | number | 24000 | Audio sample rate in Hz (optional). |
Outputs
| Status | Type | Default | Description |
|---|---|---|---|
audio chunks | binary | - | Raw synthesized audio data in the requested format (wav, mp3, etc.). |
done | JSON | - | Completion message indicating synthesis is finished. |
error | JSON | - | Error message if synthesis fails. |
Audio Chunk (Binary)
Binary audio data (WAV/MP3 format)
Example: 4096 bytes of audio data per chunk
Done Message
{
"type": "done",
"message": "Speech synthesis completed"
}
Error Message
{
"type": "error",
"message": "Invalid API key",
"code": "AUTH_ERROR"
}