
Speech-to-Text Service
Convert spoken audio into accurate transcripts using flexible endpoints. Use /v1/audio/transcribe for streaming SSE results, /v1/audio/transcribe_ws for real-time WebSocket streaming, /v1/audio/transcribe_file + GET /v1/audio/transcribe_status/{request_id} for web-only batch jobs up to 10 minutes, /v1/audio/transcribe/diarize + GET /v1/audio/transcribe/diarize/status/{job_id} for speaker-labeled transcription up to 30 minutes, and GET /v1/audio/transcribe/config to inspect supported formats and defaults before uploading.
Need an API Key? If you don't have an API key yet, you can create one here: https://playground.induslabs.io/register
Available languages
- English
en - Spanish
es - French
fr - German
de - Italian
it - Portuguese
pt - Russian
ru - Japanese
ja - Korean
ko - Chinese
zh - Arabic
ar - Hindi
hi - Turkish
tr - Polish
pl - Dutch
nl - Swedish
sv - Danish
da - Norwegian
no - Finnish
fi - Czech
cs - Slovak
sk - Hungarian
hu - Romanian
ro - Bulgarian
bg - Croatian
hr - Slovenian
sl - Estonian
et - Latvian
lv - Lithuanian
lt - Maltese
mt - Irish
ga - Welsh
cy - Icelandic
is - Macedonian
mk - Albanian
sq - Azerbaijani
az - Kazakh
kk - Kyrgyz
ky - Uzbek
uz - Tajik
tg - Amharic
am - Burmese
my - Khmer
km - Lao
lo - Sinhala
si - Nepali
ne - Bengali
bn - Assamese
as - Odia
or - Punjabi
pa - Gujarati
gu - Tamil
ta - Telugu
te - Kannada
kn - Malayalam
ml - Thai
th - Vietnamese
vi - Indonesian
id - Malay
ms - Filipino/Tagalog
tl
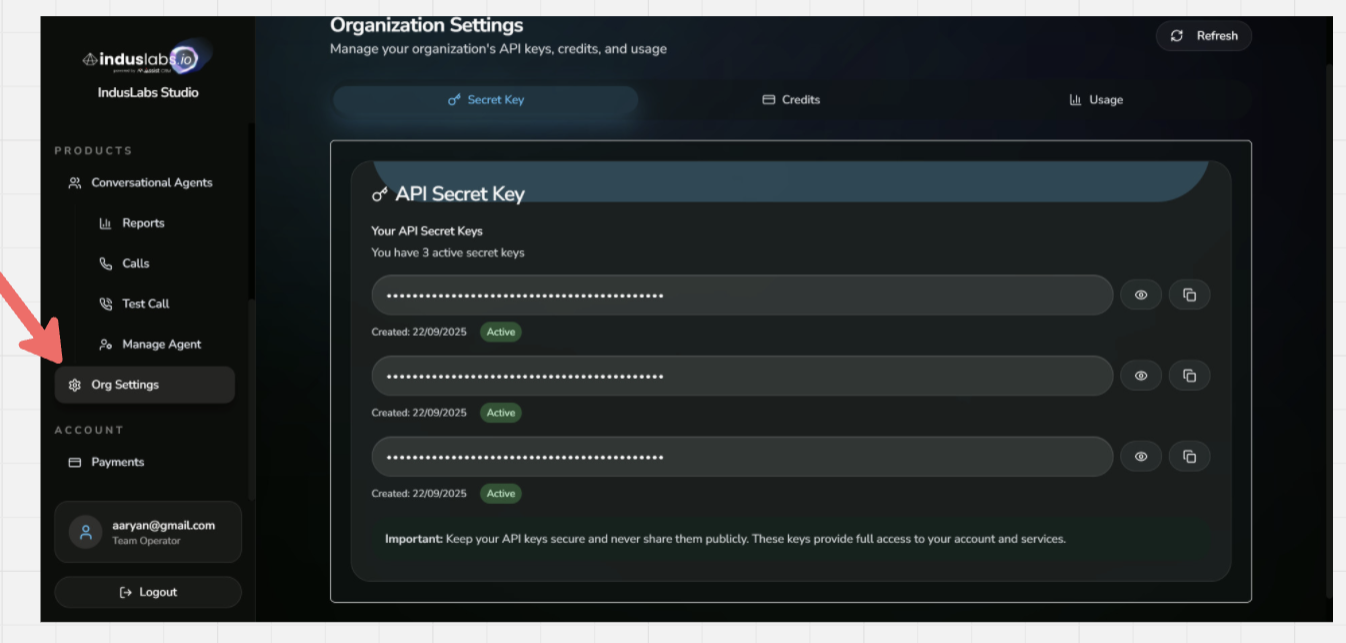
Screenshot: where to find your API key. Create one at playground.induslabs.io/register
Swarmitra (Emotional Models)
Unlock deeper insights with swarmitra-v2. These specialized models go beyond transcription to detect emotional nuance in Hindi and English speech.
Supported Emotions
Sample 1: English (Ghost Story)
Sample 2: English (Conversation)
Sample 3: Hindi (Work Pressure)
Use these models seamlessly with existing endpoints:
transcribe_ws(Real-time streaming)transcribe_file(Batch processing)
Real-time Usage
import asyncio
import websockets
import json
async def transcribe_ws():
# Pass API key and parameters in the URL query string
params = {
"api_key": "YOUR_API_KEY",
"model": "swarmitra-v2",
"language": "hindi",
"streaming": "false",
"noise_cancellation": "false"
}
query_string = "&".join([f"{k}={v}" for k, v in params.items()])
uri = f"wss://voice.induslabs.io/v1/audio/transcribe_ws?{query_string}"
async with websockets.connect(uri) as ws:
# Read and send audio in chunks
with open("emo_hi.wav", "rb") as f:
while chunk := f.read(4096):
await ws.send(chunk)
# Signal end of audio with __END__ marker
await ws.send(b"__END__")
# Receive transcription results
async for message in ws:
data = json.loads(message)
msg_type = data.get("type")
if msg_type == "chunk_interim":
print(f"[interim] {data.get('text', '')}")
elif msg_type == "chunk_final":
print(f"[chunk] {data.get('text', '')}")
elif msg_type == "final":
print(f"\n[final] {data.get('text', '')}")
break
asyncio.run(transcribe_ws())
Note: The WebSocket endpoint supports audio files up to 30 seconds. For longer audio files, use transcribe_file for batch processing (available in the dropdown on the right).
/v1/audio/transcribeTranscribe Audio (Streaming)
This endpoint is used to transcribe audio files into text with streaming results via Server-Sent Events (SSE).
- Accepts an audio file and returns real-time transcription results.
- Outputs partial, chunk-level, and final transcripts as the audio is processed.
- Suitable for low-latency transcription where results are streamed back continuously.
Form Fields
| Name | Type | Default | Description |
|---|---|---|---|
file | file | required | Audio file to transcribe. |
api_key | string | required | Authentication API key. |
language | string | - | Language code (e.g., "en", "hi") for forced detection. |
chunk_length_s | number | - | Length of each chunk in seconds (1–30). |
stride_s | number | - | Stride between chunks in seconds (1–29). |
overlap_words | integer | - | Number of overlapping words for context handling (0–20). |
Outputs
| Status | Type | Description |
|---|---|---|
200 OK | text/event-stream | Returns transcription results in JSON (streamed via SSE). |
422 Validation Error | application/json | Validation failure. Inspect detail array. |
200 OK (SSE stream)
data: {"type": "partial", "word": "यह", "provisional": true, "chunk_start": 0.0, "chunk_end": 3.413375, "chunk_index": 1, "total_chunks": 1}
data: {"type": "partial", "word": "एक", "provisional": true, "chunk_start": 0.0, "chunk_end": 3.413375, "chunk_index": 1, "total_chunks": 1}
data: {"type": "partial", "word": "टेस्ट", "provisional": true, "chunk_start": 0.0, "chunk_end": 3.413375, "chunk_index": 1, "total_chunks": 1}
data: {"type": "chunk_final", "text": "यह एक टेस्ट है, भाषन से पाट रूपांतरन का परिच्छन।", "chunk_start": 0.0, "chunk_end": 3.413375, "chunk_index": 1, "total_chunks": 1}
data: {"type": "final", "text": "यह एक टेस्ट है, भाषन से पाट रूपांतरन का परिच्छन।", "audio_duration_seconds": 3.413375, "processing_time_seconds": 1.44447922706604, "first_token_time_seconds": 0.136627197265625, "language_detected": "hi", "request_id": "df3a5974-6b24-4b15-a9d9-7c9df9513306"}
200 OK (Config)
{
"model_id": "openai/whisper-large-v3",
"supported_formats": ["wav", "mp3", "mp4", "m4a", "flac", "ogg"],
"max_file_size_mb": 25,
"hindi_model": {
"enabled": true,
"model_id": null
},
"defaults": {
"chunk_length_s": 6.0,
"stride_s": 5.9,
"overlap_words": 7
},
"limits": {
"chunk_length_range": [1.0, 30.0],
"stride_range": [1.0, 29.0],
"overlap_words_range": [0, 20],
"timeout_seconds": 30
},
"supported_languages": [
"en", "es", "fr", "de", "it", "pt", "ru", "ja", "ko", "zh",
"ar", "hi", "tr", "pl", "nl", "sv", "da", "no", "fi", "cs",
"sk", "hu", "ro", "bg", "hr", "sl", "et", "lv", "lt", "mt",
"ga", "cy", "is", "mk", "sq", "az", "kk", "ky", "uz", "tg",
"am", "my", "km", "lo", "si", "ne", "bn", "as", "or", "pa",
"gu", "ta", "te", "kn", "ml", "th", "vi", "id", "ms", "tl"
],
"output_formats": {
"streaming": "Server-Sent Events (SSE) with real-time partial results",
"file": "Complete JSON response with final transcript"
},
"credit_system": {
"unit": "1 credit = 1 minute of audio",
"billing": "Based on actual audio duration, not processing time"
}
}
/v1/audio/transcribe_wsWebSocket Streaming Transcription
Real-time STT via WebSocket. Supports bidirectional streaming for live audio input.
- Persistent Connection: Maintains open WebSocket for continuous audio streaming.
- Real-time Results: Receives transcription segments as audio is processed.
- Low Latency: Optimized for live microphone input and voice applications.
- Segment Callbacks: Provides word-level and segment-level results via callbacks.
- Bidirectional: Sends audio chunks and receives transcriptions simultaneously.
- Noise Cancellation: Optional server-side denoising before inference.
Connect to: wss://voice.induslabs.io/v1/audio/transcribe_ws
Unlike REST endpoints, WebSocket maintains a persistent bidirectional connection for real-time streaming.
indus-stt-v1: Default model that supports all languages.indus-stt-hi-en: Specialized model for Hindi and English with real-time streaming input/output and very low processing time.
WebSocket Message Flow
| Message | Type | Order | Description |
|---|---|---|---|
URL Query Params | URL | connection | Pass api_key, model, language, streaming as URL query parameters when connecting. |
Audio Chunks | binary | continuous | Raw audio data sent as binary WebSocket frames (recommended: 4096 bytes per chunk). |
End Signal | binary | last | Send b"__END__" to signal audio stream completion. |
Configuration Parameters
| Name | Type | Default | Description |
|---|---|---|---|
api_key | string | required | Authentication API key passed in URL query string. |
model | string | indus-stt-hi-en | Model to use (e.g., "indus-stt-hi-en"). |
language | string | - | Language name or ISO code (e.g., "english", "hindi", "en", "hi"). |
streaming | string | "true" | Use "true" for streaming mode (interim results), "false" for non-streaming. |
noise_cancellation | string | "false" | Use "true" to enable noise cancellation for cleaner audio in noisy environments. Filters low-frequency rumble, high-frequency hiss, and ambient background noise to reduce hallucinations and improve accuracy. |
Outputs
| Status | Type | Description |
|---|---|---|
chunk_interim | JSON | Interim transcription result during processing (when streaming="true"). |
chunk_final | JSON | Final transcription for a processed audio chunk. |
final | JSON | Complete transcription with full text after all chunks processed. |
error | JSON | Error message if processing fails. |
Chunk Interim Response
{
"type": "chunk_interim",
"text": "यह एक टेस्ट है"
}
Chunk Final Response
{
"type": "chunk_final",
"text": "यह एक टेस्ट है, भाषन से पाट रूपांतरन का परिच्छन।",
"chunk_index": 1,
"total_chunks": 1
}
Final Response
{
"type": "final",
"text": "यह एक टेस्ट है, भाषन से पाट रूपांतरन का परिच्छन।",
"audio_duration_seconds": 3.413375,
"language_detected": "hi",
"request_id": "df3a5974-6b24-4b15-a9d9-7c9df9513306"
}
Error Response
{
"type": "error",
"message": "Invalid API key",
"code": "AUTH_ERROR"
}
/v1/audio/transcribe_fileTranscribe Audio File (Batch Async)
Launches background transcription for files up to 10 minutes and immediately returns a request_id to poll later.
- Designed for long recordings up to 10 minutes (600 seconds).
- Returns immediately so your UI can poll the status endpoint or notify the user.
- Available via REST on the web — SDK helpers are not yet available.
- Supports optional noise cancellation before inference begins.
Form Fields
| Name | Type | Default | Description |
|---|---|---|---|
file | file | required | Audio file up to 10 minutes (600 seconds). |
api_key | string | required | Authentication API key. |
model | string | "default" | Use "default", "indus-stt-v1", "hi-en", or "indus-stt-hi-en". |
language | string | - | Language hint (ISO code or name). |
noise_cancellation | boolean | false | Enable server-side denoising before inference. |
Outputs
| Status | Type | Description |
|---|---|---|
202 Accepted | application/json | Returns request_id, duration, estimated_time, and status_url for polling. |
400 Bad Request | application/json | Audio rejected (e.g., longer than 10 minutes or invalid format). |
401 / 402 | application/json | Authentication failure or insufficient credits. |
202 Accepted (Batch Upload)
{
"request_id": "13c8b15a-59f9-4cda-a3bb-3bf06f5e2c9b",
"status": "processing",
"message": "File uploaded successfully. Processing in background.",
"duration": 126.42,
"estimated_time": 18.96,
"status_url": "/v1/audio/transcribe_status/13c8b15a-59f9-4cda-a3bb-3bf06f5e2c9b",
"poll_interval": 5
}
/v1/audio/transcribe_status/{request_id}Get Batch Transcription Status
Polls the progress of a batch job created by /v1/audio/transcribe_file and returns the final transcript when completed.
- Call every poll_interval seconds until the job reports completed or failed.
- Completed responses include full text, segments, word-level timestamps (if available), and processing metrics.
- Failed jobs return an error string so that you can surface actionable feedback to users.
Form Fields
| Name | Type | Default | Description |
|---|---|---|---|
request_id | path | required | Identifier returned from /v1/audio/transcribe_file. |
api_key | string (query) | required | Same key used when creating the job. |
Outputs
| Status | Type | Description |
|---|---|---|
200 OK | application/json | Current status plus transcript, segments, and metrics when completed. |
404 Not Found | application/json | Unknown or expired request_id. |
500 Internal Server Error | application/json | Job failed; see error field for details. |
200 OK (Batch Status)
{
"request_id": "13c8b15a-59f9-4cda-a3bb-3bf06f5e2c9b",
"status": "completed",
"progress_percentage": 100,
"progress": "3/3",
"text": "Final transcription text...",
"segments": [
{"text": "segment text", "start": 0, "end": 12.5}
],
"processing_time": 98.11,
"model": "indus-stt-v1"
}
/v1/audio/transcribe/diarizeDiarize + Transcribe (Async)
Uploads audio for speaker diarization and per-speaker transcription, returning a job_id for polling.
- Runs speaker diarization before transcription to label speakers.
- Supports files up to 30 minutes; processing occurs in the background.
- Use config_json to tune language, noise_cancellation, padding, and concurrency parameters.
- Returns an estimated_time and status_url so clients can poll without blocking.
Form Fields
| Name | Type | Default | Description |
|---|---|---|---|
file | file | required | Audio file to diarize (max 30 minutes). |
api_key | string | required | Authentication API key. |
config_json | string | "{}" | Optional JSON string to tune language, models, padding, and concurrency. |
Outputs
| Status | Type | Description |
|---|---|---|
200 OK | application/json | Returns job_id, estimated_time, and status_url for polling diarization results. |
400 Bad Request | application/json | Invalid audio, malformed config_json, or duration beyond 30 minutes. |
401 / 402 | application/json | Authentication failure or insufficient credits. |
503 Service Unavailable | application/json | Credit service unavailable. |
200 OK (Diarization Upload)
{
"job_id": "7a5f2f0e4c8d4b2ab6d2c5d0fdc4b5e0",
"status": "processing",
"message": "File uploaded successfully. Processing in background.",
"duration": 312.44,
"estimated_time": 93.73,
"status_url": "/v1/audio/transcribe/diarize/status/7a5f2f0e4c8d4b2ab6d2c5d0fdc4b5e0",
"poll_interval": 5
}
/v1/audio/transcribe/diarize/status/{job_id}Get Diarization Status
Polls the progress of a diarization + transcription job created by /v1/audio/transcribe/diarize.
- Poll every poll_interval seconds until status is completed or failed.
- Completed responses return per-speaker utterances with start/end timestamps and transcript text.
- Failed jobs include an error string so you can surface actionable feedback.
Form Fields
| Name | Type | Default | Description |
|---|---|---|---|
job_id | path | required | Identifier returned from /v1/audio/transcribe/diarize. |
api_key | string (query) | required | Same key used when creating the job. |
Outputs
| Status | Type | Description |
|---|---|---|
200 OK | application/json | Current diarization status plus speaker-labeled results when completed. |
404 Not Found | application/json | Unknown or expired job_id. |
401 Unauthorized | application/json | Invalid API key. |
503 Service Unavailable | application/json | Credit service unavailable. |
200 OK (Diarization Status)
{
"job_id": "7a5f2f0e4c8d4b2ab6d2c5d0fdc4b5e0",
"status": "completed",
"results": [
{
"utterance_index": 1,
"start_sec": 0.0,
"end_sec": 14.2,
"duration_sec": 14.2,
"speaker": "speaker_0",
"endpoint": "transcribe_file",
"text": "Welcome everyone, let's review the agenda.",
"status": "completed"
},
{
"utterance_index": 2,
"start_sec": 14.2,
"end_sec": 29.8,
"duration_sec": 15.6,
"speaker": "speaker_1",
"endpoint": "transcribe_ws",
"text": "I will cover the launch metrics next.",
"status": "completed"
}
],
"processing_time": 108.51,
"model": "diarization"
}
/v1/audio/transcribe/configRetrieve Transcription Configuration
Fetch default parameters, limits, and supported formats before sending audio for transcription.
- Provides current defaults for chunk sizing, stride, and overlap handling.
- Lists accepted media formats and the maximum upload size in megabytes.
- Use these values to validate client-side settings and avoid failed uploads.
Outputs
| Status | Type | Description |
|---|---|---|
200 OK | application/json | Returns defaults, limits, and supported languages/formats for the STT service. |
422 Validation Error | application/json | Validation failure. Inspect detail array. |
422 Validation Error
{
"detail": [
{
"loc": ["string", 0],
"msg": "string",
"type": "string"
}
]
}
200 OK (Config)
{
"model_id": "openai/whisper-large-v3",
"supported_formats": ["wav", "mp3", "mp4", "m4a", "flac", "ogg"],
"max_file_size_mb": 25,
"hindi_model": {
"enabled": true,
"model_id": null
},
"defaults": {
"chunk_length_s": 6.0,
"stride_s": 5.9,
"overlap_words": 7
},
"limits": {
"chunk_length_range": [1.0, 30.0],
"stride_range": [1.0, 29.0],
"overlap_words_range": [0, 20],
"timeout_seconds": 30
},
"supported_languages": [
"en", "es", "fr", "de", "it", "pt", "ru", "ja", "ko", "zh",
"ar", "hi", "tr", "pl", "nl", "sv", "da", "no", "fi", "cs",
"sk", "hu", "ro", "bg", "hr", "sl", "et", "lv", "lt", "mt",
"ga", "cy", "is", "mk", "sq", "az", "kk", "ky", "uz", "tg",
"am", "my", "km", "lo", "si", "ne", "bn", "as", "or", "pa",
"gu", "ta", "te", "kn", "ml", "th", "vi", "id", "ms", "tl"
],
"output_formats": {
"streaming": "Server-Sent Events (SSE) with real-time partial results",
"file": "Complete JSON response with final transcript"
},
"credit_system": {
"unit": "1 credit = 1 minute of audio",
"billing": "Based on actual audio duration, not processing time"
}
}